Top 6 Myths Associated with Blockchain Technology

Of late, the blockchain technology has emerged as a revolutionary tool spurring acute interest amid the data community. Also known as the ‘distributed ledger’ technology, blockchain provides a way of recording digital transactions in a way that is crafted to be transparent, secure and efficient. The technology is robust and young. In the next few years, it is expected to hit the mainstream and drive commercialization.
No wonder, the blockchain technology is secure and full of positive outcomes yet there exist too much confusion and misunderstanding regarding its essence.
Myth 1: Blockchain is a database full of magical powers
Blockchain is nothing but a simple list of transaction journals – “This list is ‘append only so entries are never deleted, but instead, the file grows indefinitely and must be replicated in every node in the peer-to-peer network”. It doesn’t make room for any sort of physical data storage, like a PDF file or Word document.
Myth 2: Blockchain is the next big change (for good)
Of course, Blockchain is used to perform technical and intricate transactions. It works wonderfully when it comes to mitigating the risk of online fraud, nevertheless, it doesn’t completely eradicate the risks imposed by fraudsters. Thus, it also raises questions on data confidentiality.
Myth 3: Blockchain is free
Although people assume that blockchain is free, the hard fact is that it is neither inexpensive nor highly efficient – YET. It involves several computers to solve myriad mathematical algorithms to formulate a single immutable result, which is eventually known as the Single Version of Truth (SVT).
Myth 4: A single blockchain is in existence
Blockchain is a collective term used for different technologies that are closed or open sourced, available in private or public versions and serve a general-purpose or customized as per needs. However, the common element observed in all of them is that they follow a consensus mechanism and is fleeced up by crypto. Ethereum, Corda, Hyperledger, Bitcoin’s Blockchain and IBM and Microsoft’s Blockchain-as-a-service are all a part of Distributed Ledger Technologies.
Myth 5: Blockchain is the ultimate power technology
Of course, the code is powerful but it’s no magic. Bitcoin and blockchain technologies will definitely lead the future but their authority is limited to mathematics. They won’t replace the job roles of government or lawyers. Cryptocurrency is the fulcrum of blockchain and it’s still far from becoming mainstream.
Myth 6: Blockchain is used only in the financial sector
As a matter of fact, the first application of Blockchain was indeed a bitcoin cryptocurrency, which is a product of the financial sector. Nevertheless, the revolutionary technology has diverse applications across numerous sectors, including finance. Besides finance, blockchain is widely leveraged in healthcare, real estate and FMCG sectors.
At present, Blockchain Technology is evolving at a steadfast rate. Each day, volumes of data records are being created. Such humongous amounts of data need efficient management. For that, the Internet of Things is the key. Dexlab Analytics is a premier Data Science training institute in Gurgaon and we cover a plethora of in-demand skill training courses.
Interested in a career in Data Analyst?
To learn more about Data Analyst with Advanced excel course — Enrol Now.
To learn more about Data Analyst with R Course — Enrol Now.
To learn more about Big Data Course — Enrol Now.
To learn more about Machine Learning Using Python and Spark — Enrol Now.
To learn more about Data Analyst with SAS Course — Enrol Now.
To learn more about Data Analyst with Apache Spark Course — Enrol Now.
To learn more about Data Analyst with Market Risk Analytics and Modelling Course — Enrol Now.
Dexlab’s Datacember is a Special Christmas Gift for College Students

DexLab Analytics is quite a reputable name in the sector of data analytics trainings in India. They are also known for their online live training courses and for their unique offerings of free demo sessions. With data science and analytics being deemed as the sexiest job in the 21st century, it only makes sense that it gathering a lot of attention from young and ambitious youth ready to start their careers.
Until now the field of analytics training was mostly known for people with preliminary or specialized degrees. But DexLab Analytics with their latest winter admission offer called – DexLab’s Datacember is hoping to change that trend. They believe that analytics training should be started from the very beginning of professional education, as the subject is highly complex and needs practice.
DexLab’s #Datacember
They are trying to entice the students with this new promotional admission offer to make the career of data analytics seem lucrative and with a lot of scope for success, which is the fact in the present market. The admission offer can be availed by students of colleges from any relevant fields and will only require the furnishing of a student ID. The courses on which the offers are applicable are the following Business Analyst Certification, Data Science, Big Data Hadoop for Classroom Training only at Gurgaon & Pune.
The offer up for grabs in DexLab’s Datacember drive is that for a single entry of a student, a discount of 10% can be availed on the course fees; but for entry of students 3 or more a discount of 30% each on the admission fees can be obtained.
The date of registration for this offer is from 7th December 2016 to 14th January 2017. The Datacember offer will remain valid for December 2016 to March 2017.
The CEO of DexLab spoke on this initiative by saying, “In light of the same the institute has launched DexLab’s Datacember – a campaign which offers to provide college students with attractive discounts to help them acquire these talents easily.”
Furthermore, the institute also plans to conduct corporate trainings and collaborate with their long-time training partners RCPL along with several hundreds of other colleges and Universities in India; for conducting workshops and corporate trainings on the topics related to data science and Big Data Analytics. This corporate training collaboration is dated to start from the 10th of December and will go on until the 18th December 2016. The training sessions will of 40 hours each and will cover the topics of R Programming, Analytics using R and Data Science.
The first training session is about to take place at an engineering college in Bhubaneswar, Orissa for their client RCPL.
About DexLab Analytics:
Founded by a team of core industry experts with several years of experience in the field of data science and analytics, their institute has been around since the beginning of the Big Data buzz. They are a reputable institute based in Gurgaon and Pune who are known for quality training and placement support for their students.
Contact Details:
DexLab Solutions Corp.
G. Road, Gurgaon 122 002, Delhi NCR
+91 852 787 2444
+91 124 450 2444
DexLab Solutions Corp.
Gokhale Road, Model Colony, Pune – 411016
+91 880 681 2444
+91 206 541 2444
hello@dexlabanalytics.com
How to Write and Run Your First Project in Hadoop?

It may be easy to run MapReduce on small datasets without any fuss over coding and fiddling, but the only condition being you know what to do. And here is what you should know:
It may be already known to you that MapReduce works on a conceptual level. In this blog post we will discuss how you can write code that will run on Hadoop and that will start with a MapReduce program using Java.
The development environment:
To begin with we will need Java (we are using Oracle JDK 6), Git, Hadoop and Mit. You can download the latest stable version of Apache Hadoop (1.0.4) online from there release page, and then extract it to a place suitable for you.
This is what we did on our computer:
% tar zxf hadoop-1.0.4.tar.gz
% export HADOOP_HOME=$(pwd)/hadoop-1.0.4
% $HADOOP_HOME/bin/hadoop version
Hadoop 1.0.4
Then visit another directory and find the Git repository that compliments this article:
% git clone git://github.com/tomwhite/hadoop-drdobbs.git
% cd hadoop-drdobbs
% mvn install
You will find that this repository also has a small amount of sample data suitable for testing. Like this:
% cat data/*.tsv
dobbs 2007 20 18 15
dobbs 2008 22 20 12
doctor 2007 545525 366136 57313
doctor 2008 668666 446034 72694
The file has a few lines from the Google Books Ngram Dataset. For clarity here’s what they are: the first line has the word “dobbs” which appeared in the books from 2007 about 20 times almost and these occurrences were noted in more than 18 pages in 15 books.
Writing the Java MapReduce:
To find the total count for each word let us begin to write the MapReduce job. We will begin with the map function which in Java is represented with an instance of org.apache.hadoop.mapreduce.Mapper.
As a first step you must decide about the mapper is the types of the input key-value pairs and the output-key-value pairs. For the declaration of the Mapper class, here it is:
public class Mapper
As we are going to process the text, we will use the TextInputFormat. This will help us determine the input types, like LongWritable and Text, both of these are found in the org.apache.hadoop.io package. These types of Writables act as wrappers around the standard types in Java (in this case they are, long and string), this has been optimized for efficiency of serialization.
But authors of the MapReduce programs can use the Writable types without having to think about serialization. The only time they may need to consider serialization is when they write a custom Writable type. And when in such circumstances it is recommended to use a serialization library like Avro.
Coming back to the input type we can help present the input to our mapper with TextInputFormat as Longwritable, Text and pairs like this:
(0, “dobbs 2007 20 18 15”)
(20, “dobbs 2008 22 20 12”)
(40, “doctor 2007 545525 366136 57313”)
(72, “doctor 2008 668666 446034 72694”)
The key here is to use the offset within the file, and the content of the line is the value. As the mapper it is your job to extract the word along with the number of occurrences and ignore the rest. So, the output would be (word, count) pairs, of type (Text, LongWritable). The signature of the mapper should look like this:
public class ProjectionMapper extends Mapper
Then the only thing left for us to do is to write the implementation of the map() method. The source for the whole mapper class would appear in Listing One (ProjectionMapper.java).
Here’s what the Listing One: ProjectionMapper. Java looks like:
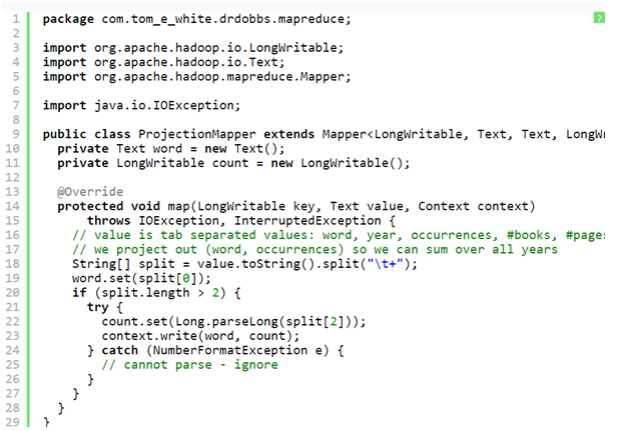
But there are certain things that one must know about this code.
- There are two instance variables, count and word which have been used to store the map output key and value.
- The map () method is known as once per input record, so it works to avoid unnecessary creation of objects.
- The map () body is pretty straightforward: it is used to split the tab-separated input line into the fields. It uses the first field as word and the third one as count.
- The map output is written with the use of the write method in the Context.
For the sake of simplicity we have built the code to ignore the lines with an occurrence field which is not a number, but there are several other actions one could take. However there are some other actions that one could take. For instance, incrementing a MapReduce counter to track how many lines are affected by it. To know more about this see, getCounter() method on Context for more information. After running through our small dataset, the map output would look like this:(“dobbs”, 20)
(“dobbs”, 22)
(“doctor”, 545525)
(“doctor”, 668666)
You must understand that Hadoop will transform the map output so that values can be brought together for a given key. The process is called the shuffle. For our abstract representation, the inputs or reducing the steps will seem somewhat like this:
(“dobbs”, [20, 22])
(“doctor”, [545525, 668666])
Most of our reduce implementation will have something to do with sum of the counts. We will require an implementation of the org.apache.hadoop.mapreduce. The reducer should be used with the following signature:
public class LongSumReducer extends Reducer<
Text, LongWritable, Text, LongWritable>
We can also try to write the code on our own, but with Hadoop we do not need to, as it comes with an implementation which is shown below in the Listing Two (LongSumReducer.java):
Listing two: LongSumReducer.java (code obtained from Apache Hadoop project) would look like this:
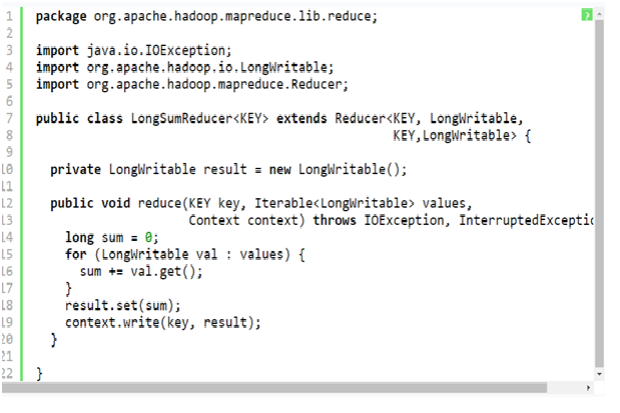
A noteworthy point to be mentioned here is, that reduce () method signature is slightly different from the map () one. That is because it contains an iterator over the values rather than just a single value. This will showcase the grouping that the framework would perform on the values for a key.
The implementation is fairly simple in the LongSumReducer: it sums the values and then writes the total out using the same key as the input.
The output for the reducer will be:
(“dobbs”, 42)
(“doctor”, 1214191)
This was the first part of this blog, for the rest of the step follow our next blog post from the premiere SAS training centre in Pune. In the next blog tranche we will reveal the procedures for the Listing three and the actual running of the job.
Interested in a career in Data Analyst?
To learn more about Machine Learning Using Python and Spark – click here.
To learn more about Data Analyst with Advanced excel course – click here.
To learn more about Data Analyst with SAS Course – click here.
To learn more about Data Analyst with R Course – click here.
To learn more about Big Data Course – click here.
You Must Learn Hadoop for These 5 Reasons

Industry insiders revealed that a Big Data Hadoop certification can make all the difference between having a dream job role and a successful career with being left behind. As per Dice all technology professionals should start volunteering for major Big Data projects which will make them more valuable to their present firms and also make them more marketable to other employers.
As per a Forbes report released in 2015, about 90 percent of global companies reported to have made medium to high levels of investment into Big Data Analytics and out of them about one third of the companies described their investments as highly important. Also about two thirds of these businesses reported that these analytics initiatives with Big Data have had a significant and measurable impact on their revenues.
People who have undergone Big Data Hadoop training are highly in demand and this is undeniable in today’s times. Thus, for IT professionals it is imperative to keep themselves abreast with the latest in trends in the Hadoop and other Big Data analytics technologies.
The main advantages with an Apache Hadoop certification to ramp your career can be summarised as the following:
- Accelerated career growth
- An increment in pay packages for having skills in Hadoop
So, it is evident that a career in Hadoop will pay well and is no rocket science.
Apache Hadoop courses offer increased job opportunities:
Assessing the Big Data market forecast the industry seems more than promising and the upward trends are clearly visible which is projected to keep progressing with time. It is safe to say that the job trend or a market phenomenon is not a short-lived feature. That is because Big Data and its technologies are here to stay. And Hadoop has the potential to improve job prospects for people whether they are fresher or an experienced professional.
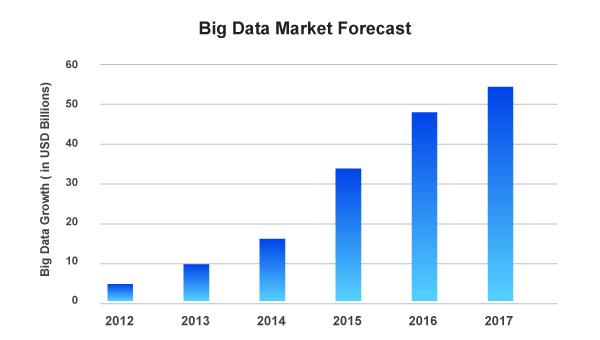
Big Data Market Forecast
Avendus Capital released a research report which estimates that the IT market for Big Data analytics in India is floating around USD 1.15 billion during the end of 2015. This contributed to about 1/5th of the KPO market which is worth USD 5.6 billion. Moreover, the Hindu made a prediction which suggests that by the conclusion of the year 2018, India solely will face with a shortage as close to 2 Lakh of Data Scientists. This should present the people with tremendous career and growth opportunities.
This huge skill gap within Big Data can be bridged only by efficient learning of Apache Hadoop which enables professionals and freshers alike to add value to their resumes with Big Data skills.
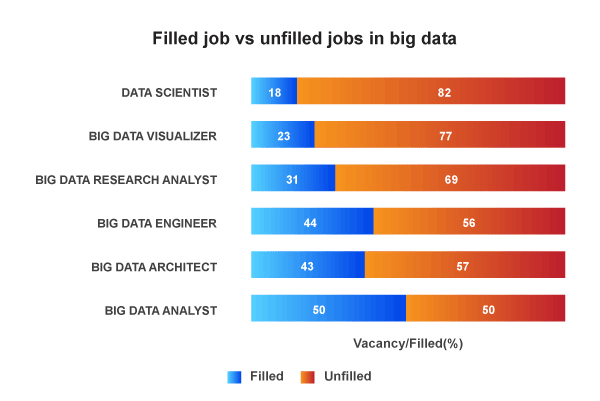
Filled Job VS Unfilled Jobs in Big Data Analyst
Thus, this is the perfect opportunity for you to take maximum advantage of a Big Data Hadoop course to reap the benefits of this positive market trend.
Who is employing Hadoop professionals?
The best place to get information on the number of existing Hadoop professionals and whose hiring is to go on LinkedIn. The graph displayed above talks about the titles of Hadoop professionals who are being hired by the top companies and which has the maximum vacancy ratio.
The word around the market is that Yahoo! is leading this rat race.
Big Data Hadoop will bring about the big bucks:
According to Dice, technology professionals should begin volunteering for the Big Data projects, which will make them more valuable to their current employing organization and make them more marketable to other employers.
Companies around the world are betting big that harnessing data can play a huge role in their competitive plans and that is leading to the high pay for their in-demand, critical skills.
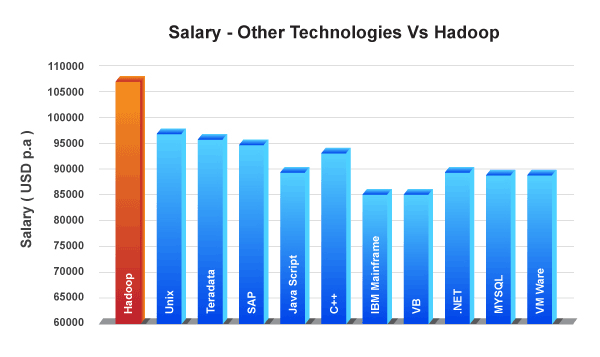
Salary – Other Technologies Vs Hadoop
As per the Managing Director of Dice, Hadoop is the leader in Big Data category in terms of job postings. And according to Dice, Hadoop professionals can make an average of USD 120,754 which is more than what Big Data jobs pay which is about USD 108,669.
Top companies that are hiring Hadoop pros:

Top Companies That are Hiring Hadoop Pros:
Interested in a career in Data Analyst?
To learn more about Machine Learning Using Python and Spark – click here.
To learn more about Data Analyst with Advanced excel course – click here.
To learn more about Data Analyst with SAS Course – click here.
To learn more about Data Analyst with R Course – click here.
To learn more about Big Data Course – click here.
Telecom Industry is Cashing on Big Data Analytics
The term telecom is a very big word in the business world today, especially with the concept net neutrality which has flooded all over the world over the past few months.
How adoption rates are increasing at light speed:
The issue of whether companies should create hierarchical internet services is still a matter of debate, but still there is one technology that all the giants in the telecom industry like AT&T, Verizon and Comcast are using, to capitalize on their competitive advantages. If they can get access to the data that circulates through their networks in each second, then they can find better ways to deliver phone, internet and television services. So, why not analyse the heck out of that data?
After all it is a fact that telecommunications companies have built their very business on information. So, this should not come as a surprise that they would be willing to spend a lot in programs to qualitatively analyse of data.
Watch our video attached here to know more about how telecom companies ca reduce customer churn and better their service delivery:
Interested in a career in Data Analyst?
To learn more about Machine Learning Using Python and Spark – click here.
To learn more about Data Analyst with Advanced excel course – click here.
To learn more about Data Analyst with SAS Course – click here.
To learn more about Data Analyst with R Course – click here.
To learn more about Big Data Course – click here.
